
Introdução
“Vetorizei minha base textual, o que faço agora?”
Na prática, a solução nem sempre passa por arquiteturas RAG ou por acoplar uma LLM gigante. Muitas vezes tudo o que você precisa já está na sua própria stack: aproveitar os embeddings de forma nativa, tirando deles velocidade e relevância máximas.
Beleza, mas como faço isso?
Neste artigo vou te mostrar, do começo ao fim, como implementar uma busca semântica completa com embeddings, hybrid search via RRF (Reciprocal Rank Fusion), reranqueamento de resultados e recuperação inteligente — tudo isso sem precisar sair do Elasticsearch.
O que é busca semântica e por que ela importa?
Diferente de uma consulta por palavras-chave, essa abordagem transforma consultas e documentos em vetores de significado (embeddings). No espaço vetorial, itens conceitualmente semelhantes ficam próximos, mesmo quando usam vocabulário diferente. O resultado é uma recuperação que entende intenção, lida naturalmente com sinônimos e traz à tona conteúdo realmente relevante.
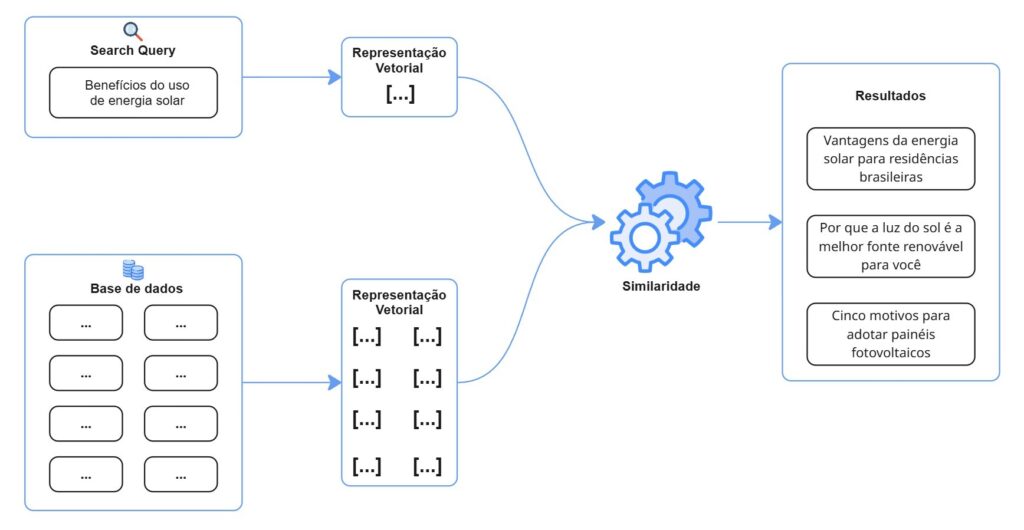
A figura abaixo ilustra o fluxo de uma busca semântica: a consulta é vetorizada, comparada aos vetores da base e retorna conteúdos de significado semelhante, mesmo sem coincidência literal de palavras.
Por que utilizar o Elasticsearch?
Costumo dizer que, com o Elasticsearch, tudo o que você precisa é da sua base textual — e ele faz o resto. Habilitando um machine-learning node você ganha, no mesmo ambiente:
- Vector database: Indexe o texto em um campo do tipo semantic_text e o Elastic gera embeddings usando o modelo que você escolher (ex.: multilingual-e5-small).
- Inference endpoints: Um mesmo modelo pode ser exposto dentro do cluster e reutilizado em mais de um contexto, por exemplo: ingest (para vetorizar documentos na indexação) e search (para otimização de buscas através de embeddings “on-the-fly” na consulta). Tudo gira no próprio nó de ML, dispensando serviços externos.
- Chunking automático: Quando um texto excede o limite de tokens do modelo, o Elastic o divide em pedaços menores e ajusta dinamicamente o tamanho de cada chunk, adicionando sobreposições que preservam o contexto entre eles. Tudo acontece nos bastidores, sem configuração manual — apesar de ter a opção, caso prefira.
- Busca semântica avançada: Combine, em uma só consulta, busca lexical, semântica e técnicas de rerank; mesmo que para isso precise de mais de um modelo de machine learning.
Base Utilizada
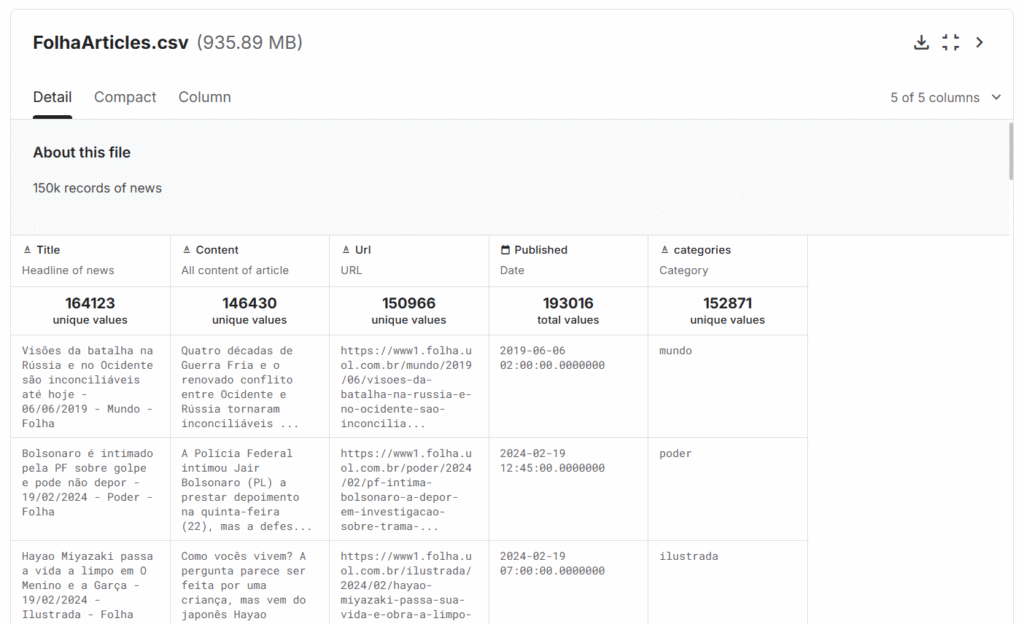
Para demonstrar este trabalho foi utilizado um dataset composto por notícias da Folha de São Paulo. Ele está acessível no Kaggle e foi disponibilizado pelo usuário luisfcaldeira.
Com aproximadamente 160 mil notícias publicadas pela Folha, cada registro possui campos como:
- Título da notícia;
- Conteúdo da notícia;
- Seção editorial;
- URL da publicação original
Os campos de título e conteúdo serão utilizados para transformações vetoriais, sendo então mapeados no índice de destino com uma cópia para um campo semantic_text.
📌 Importante: Este artigo não cobre o processo de indexação da base no Elasticsearch, já que esse não é o foco da discussão. De todo modo, a importação foi direta, sem pré-processamentos adicionais — o dataset já estava estruturado e pronto para ingestão.
Fluxo de implementação
Para fins de demonstração, desenvolvi uma estrutura simples composta por um backend em Python/FastAPI e um frontend em React, permitindo testar as consultas e visualizar os resultados de forma prática. No entanto, este artigo não se propõe a detalhar a implementação do projeto em si, e sim a explorar a metodologia e os conceitos aplicados na construção de uma busca semântica com o Elasticsearch.
Com a base importada no Elasticsearch (ainda sem as representações vetoriais dos campos de interesse), parti para a escolha do modelo responsável pela geração de embeddings. Explorando ainda mais as funcionalidades da stack, optei pela utilização do modelo E5 Multilingual, um modelo que possui cobertura da Elastic e já vem pré-configurado no cluster.
Após o deploy do modelo e a criação do endpoint, realizei o mapeamento dos campos Content_vec e Title_vec, ambos como cópias dos seus campos text originais. Agora definidos como semantic_text, esses campos serão vetorizados automaticamente pelo Elasticsearch, com base no inference endpoint configurado.
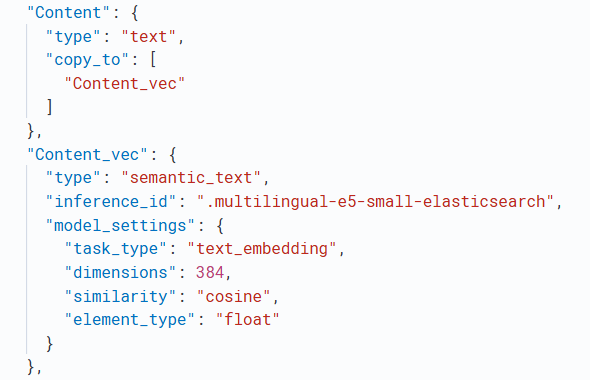
Abaixo, o mapeamento aplicado ao Content_vec, que segue a mesma estrutura usada no Title_vec:
Com o mapeamento criado, foi executado um reindex simples, apenas para que os dados já existentes passassem pelo novo mapeamento e tivessem seus embeddings gerados automaticamente. A partir disso, iniciei os testes com consultas semânticas, ajustando diferentes estratégias de recuperação.
Essa etapa é essencial para entender o que realmente faz sentido para o seu objetivo. Vale a pena experimentar variações de consulta, testar cláusulas híbridas com should, alterar pesos e explorar diferentes formas de cálculo de score.
No meu caso, optei por usar a estratégia RRF (Reciprocal Rank Fusion) combinando a similaridade vetorial dos campos Content_vec e Title_vec. A ideia de incluir o título foi uma tentativa de refinar a recuperação, trazendo uma camada extra de contexto que ajuda a orientar a busca para o assunto central da notícia — o que, na prática, contribuiu para um aumento na qualidade dos resultados e no score geral.
A consulta semântica que obtive como base final utilizou o recurso de RRF (Reciprocal Rank Fusion) para combinar os resultados de duas buscas distintas: uma baseada no conteúdo (Content_vec) e outra no título (Title_vec) dos documentos. Ambas as buscas foram filtradas por categoria, garantindo que os documentos comparados pertenciam ao mesmo contexto editorial — algo essencial para evitar ruído na comparação semântica, mas que não interferisse no score final, já que ser da mesma categoria era considerado um pré-requisito básico.
Essa abordagem se mostrou eficaz: os resultados retornados já traziam alta coerência semântica e estavam bem posicionados no ranking. Ainda assim, era perceptível que a ordem dos documentos nem sempre refletia a relevância mais refinada esperada — algo comum quando a recuperação inicial é feita apenas com embeddings.
Rerank
Foi nesse ponto que entrou a necessidade de aplicar um modelo de rerank, que reordena o top-N de forma mais criteriosa, comparando diretamente a consulta com os textos candidatos. A ideia do rerank é trazer uma camada adicional de similaridade, realizando uma análise mais direta entre o que está sendo consultado com o que foi recuperado na base pelo modelo E5. Com um número reduzido de documentos que possuem similaridade semântica, o modelo de rerank faz o refinamento da busca, re-ranqueando-os para que a recuperação de resultados siga um ordenamento de relevância que faça mais sentido.
A Elastic oferece um modelo pronto para isso, o.rerank-v1-elasticsearch, mas ao analisá-lo, não encontrei nenhuma documentação indicando suporte multilíngue. Por precaução, optei por não utilizá-lo neste cenário.
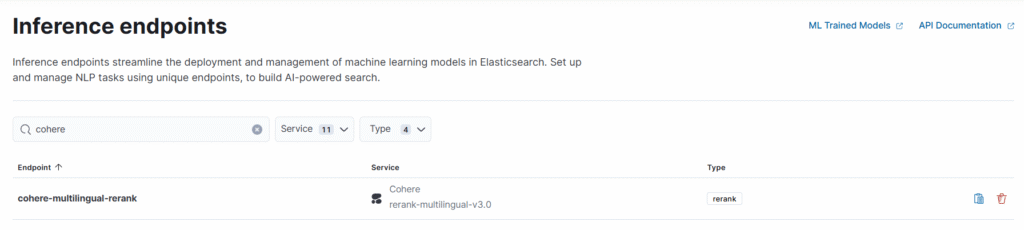
Como alternativa, recorri ao modelo da Cohere, o rerank-multilingual-v3.0. Graças à flexibilidade da stack, pôde ser integrado com facilidade: bastou criar um inference endpoint externo no Elasticsearch, apontando para o modelo da Cohere. Para isso, criei rapidamente uma conta gratuita no serviço e, com uma API Key, configurei a autenticação na criação do endpoint:

Para validar o funcionamento do modelo de rerank, segui uma abordagem apresentada em um blog post excelente que explica como aplicar reranqueamento semântico no Elasticsearch e destaca sua importância na ordenação dos resultados. Aproveito para recomendar a leitura e agradecer ao Adam Demjen e ao Nick Chow, que, com esse artigo, me ajudaram bastante a entender mais o funcionamento desta segunda etapa na recuperação de resultados. Link: Semantic reranking in Elasticsearch with retrievers
A abordagem em questão utiliza a API _inference, que permite enviar uma consulta e uma lista de documentos candidatos. O modelo, então, reordena os documentos com base na similaridade semântica em relação à consulta fornecida.
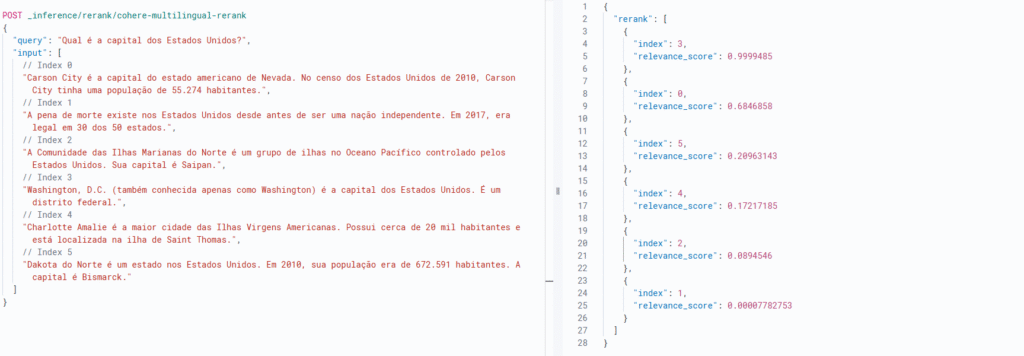
Esse método foi fundamental para validar o modelo da Cohere antes de integrá-lo à consulta principal no índice de notícias. Abaixo, a query de teste utilizada e o retorno satisfatório obtido:
Com o modelo validado, iniciei os ajustes necessários para incorporá-lo à consulta final da forma mais eficiente possível. A estratégia adotada foi envolver a estrutura existente de RRF com o retriever do tipo text_similarity_reranker, que permite aplicar o rerank sobre os documentos recuperados, com base em um campo textual específico.
No meu caso, optei por usar o título da notícia (Title) como base para o reranqueamento. Essa escolha se deu porque o título, em geral, resume bem o conteúdo da matéria, e quando os textos são semanticamente próximos, pequenas variações de escopo ou foco costumam se refletir mais claramente no título do que no corpo extenso da notícia.
No entanto, vale destacar que essa decisão pode variar conforme o caso de uso. Em outras aplicações, pode ser mais vantajoso fazer o rerank com base no corpo do texto, em um resumo, ou em outros campos específicos do índice utilizado. É importante testar diferentes combinações para entender o que entrega os melhores resultados em termos de relevância.
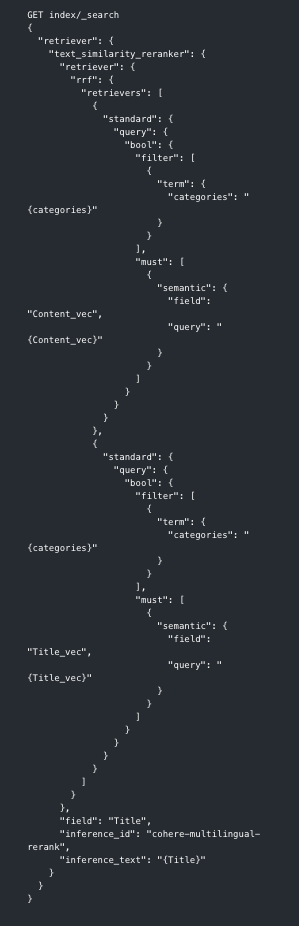
Abaixo, a estrutura final da query, que combina recuperação semântica com RRF e reranqueamento com o modelo Cohere/rerank-multilingual-v3.0, utilizando o campo Title como referência para reordenar o top N de documentos:
Resultados
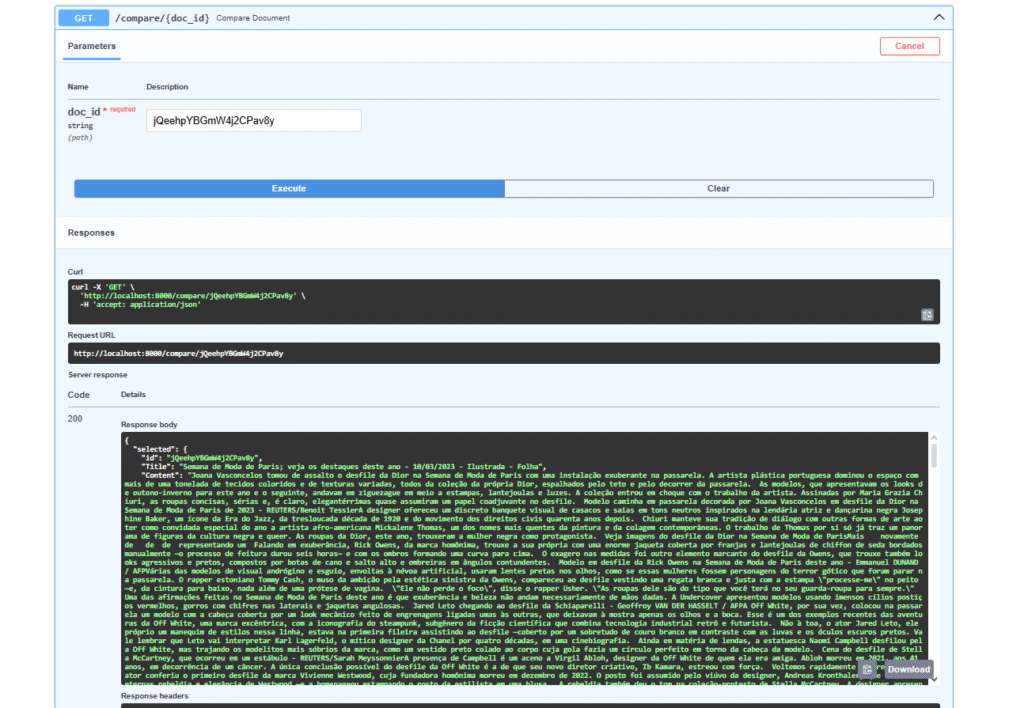
Com todas as estratégias implementadas — vetorização automática, RRF, rerank com modelo externo — o projeto ganhou forma em uma aplicação funcional. No backend, foi criado um endpoint /compare, que executa exatamente a consulta descrita na seção anterior, reunindo os recursos de recuperação e reranqueamento em um único ponto de acesso. A comparação é feita com base no valor do campo _id do documento informado, que serve como referência para buscar conteúdos semanticamente similares na base:
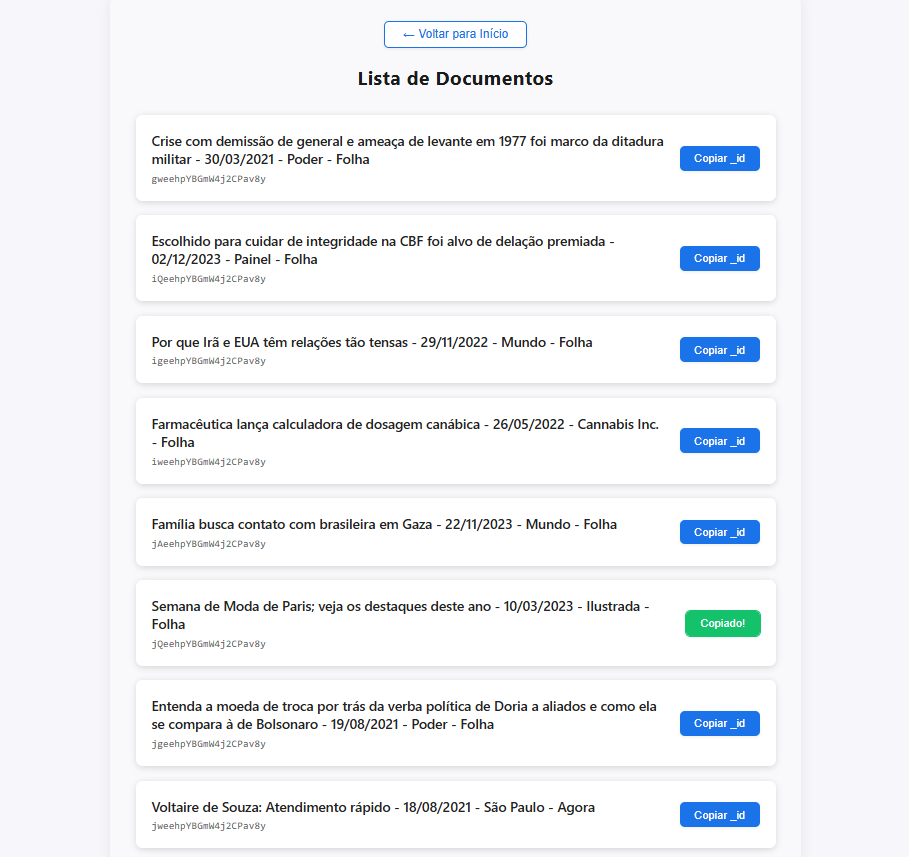
No frontend, a aplicação conta com uma página de listagem de documentos. Nela, é possível copiar o _id de uma notícia específica:
Esse _id pode então ser colado na tela de comparação, que dispara a consulta e retorna os documentos semanticamente mais similares à notícia de origem — utilizando todas as técnicas descritas ao longo do artigo.
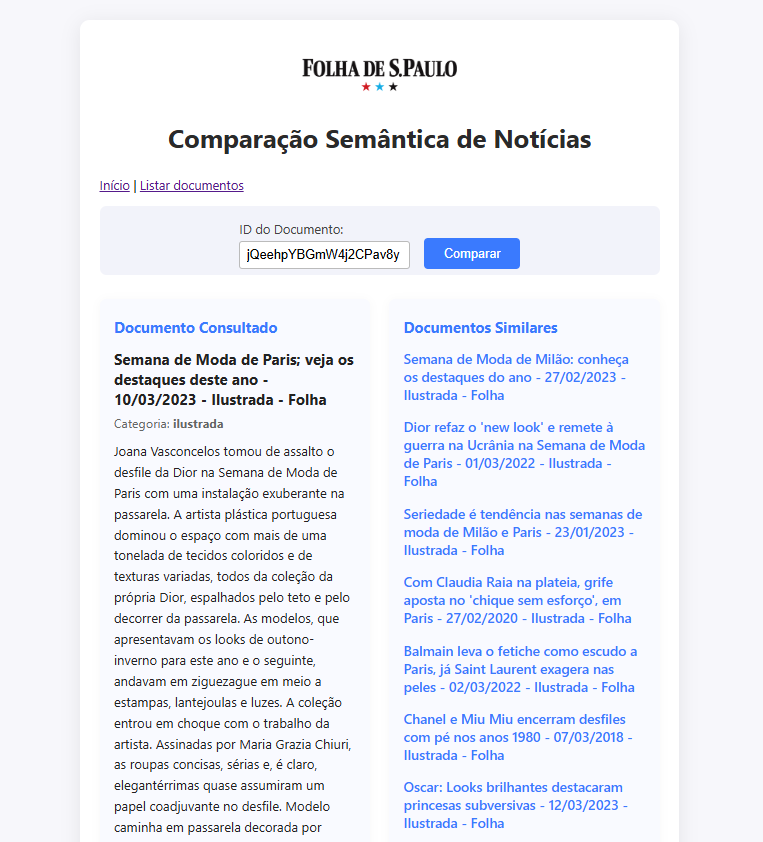
📝 Nota: como o objetivo do projeto é descobrir o que há de similar na base (e não apenas confirmar a presença da própria notícia consultada), o resultado da comparação exclui automaticamente o documento original da resposta. Para isso, alterei o output da consulta para remover qualquer item que compartilhasse o mesmo _id do documento de origem.
Conclusão e Casos de uso aplicáveis
Esse projeto torna claro que fazer busca semântica de verdade não precisa ser complicado. Com o Elasticsearch, o que antes exigia várias ferramentas e integrações pode hoje ser implementado com uma stack só — e de forma natural. Basta ter sua base textual em mãos e vontade de explorar.
E os casos de uso? Eles são muitos — e estão mais próximos do dia a dia do que parece:
- Recomendação de conteúdo: sugerir artigos, matérias ou documentos relacionados com base no que o usuário está lendo.
- Pesquisa de jurisprudência: em cenários jurídicos, encontrar decisões similares para embasar novos casos.
- Aplicações policiais e de inteligência: comparar boletins de ocorrência, registros de investigações ou denúncias para detectar recorrências ou conexões entre casos — mesmo quando descritos com linguagens diferentes.
- Deduplicação semântica: encontrar conteúdos com mensagens semelhantes, mesmo que escritos de forma distinta — útil em curadoria, auditoria ou detecção de reuso.
- Agrupamento inteligente de documentos: organizar grandes volumes textuais em grupos temáticos por similaridade de sentido.
No fim das contas, é sobre entender melhor os dados, com mais contexto e menos esforço técnico.
Abaixo, segue o link do repositório no GitHub:
🔗 Comparação Semântica com Elasticsearch
Obrigado por ter lido até aqui! Sou entusiasta — e ainda iniciante — nessa área, mas sigo explorando e aprendendo a cada projeto.
Se você curtiu o conteúdo, me chama! Vamos trocar ideias, experiências e explorar novas formas de buscar. 🔍
Statistician | Elastic Certified Engineer & Elastic Certified Analyst @ BKTech